
Github - rethought
Github? Again?
After a first post on Github, why bother with a second one?
I recently gave a presentation about all the things I learnt from two years of PhD - and that I try to somehow propagate here too. And if many things I work on could not be applied to other projects - and I would say most of what I work on cannot be directly applied to other projects from the different labs I have a step in - there is one thing that was of interest to everyone: code testing.
Learning though suffering
La Fontaine wrote short stories to illustrate moral standards, so here’s mine. In June, we submitted a paper - the most significant portion of my PhD - and it was rejected this summer as being a “minor/incremental” improvement to an overcrowded field. So I spent subsequent weeks trying to improve everything. It can be seen with roughly 50 commits throughout the month of September and a large part of the package being re-written.
This whole package was already on CRAN repository so it was already documented, and being the writer I was familiar with what I wrote… But changing bits and pieces of code can trigger chain reactions, that are not always easy to spot unless you test the behaviour of your code.
Steps in: Unit testing
Remember when we created a Travis yml in Github part 1?
Here’s the code again:
language: R
sudo: false
cache: packages
r:
- oldrel
- release
- devel
warnings_are_errors: false
r_github_packages:
- jimhester/covr
after_success:
- Rscript -e 'covr::codecov()'The strange thing here is the “after_success” part, I never said what covr::codecov was doing!
Well, the manual for once is pretty self explanatory:
“Run covr on a package and upload the result to codecov.io”
Introducing testthat
Ok, so Travis is making sure that my code compiles without errors - in R it makes sure that you can make a package out of your code. So basically, it checks if someone else could use your code. However, it does not check that what you wrote has the correct behaviour!
For example, assume I create a function SUM that has the following code:
SUM <- function(x , y){
x + y
}Then, months later, I inadvertently change it to:
SUM <- function(x , y){
x + y
x
}My function now only returns the value of x instead of x+y, and in a package with dozens if function, you may not see it right away - and why would you suspect this
function after all?
What you would like is that when you check your package you get warning saying your function does not behave in the proper way.
In R this can be easily handle with the testthat package.
In my package folder, I just have to create a “tests” folder, containing testthat.R and a testthat folder, and I can write all my tests as R code in the testthat folder. So basically the new package structure is: - codecov.yml - DESCRIPTION - man/ - NAMESPACE - R/ - tests - testthat.R - tests/ - .travis.yml Here is the code I would write in test-SUM.R
context("SUM function") # That is the general topic of test-SUM.R
test_that("SUM sums x and y",{
expect_equal(SUM(1,1),2)
}
)So when Travis/devtools::check will have finished checking your code, it will use the functions you export to execute the tests. If the test fails, you receive an error notification with the text: `testthat results ================================================================ OK: 0 SKIPPED: 0 FAILED: 1
- Failure: SUM sums x and y (@test-SUM.R#3) `
So now, you know that your code has an issue, and you can directly spot that it comes from the SUM function.
The link with codecov?
Codecov.io allows you to (nicely) visualize which part of your gihub repository is covered by unit testing, and what is not - i.e. what percentage can blow up without you noticing at your next commit. The main screen gives you an overview, but clicking on the name of a file in the “Files” folder should look like this:
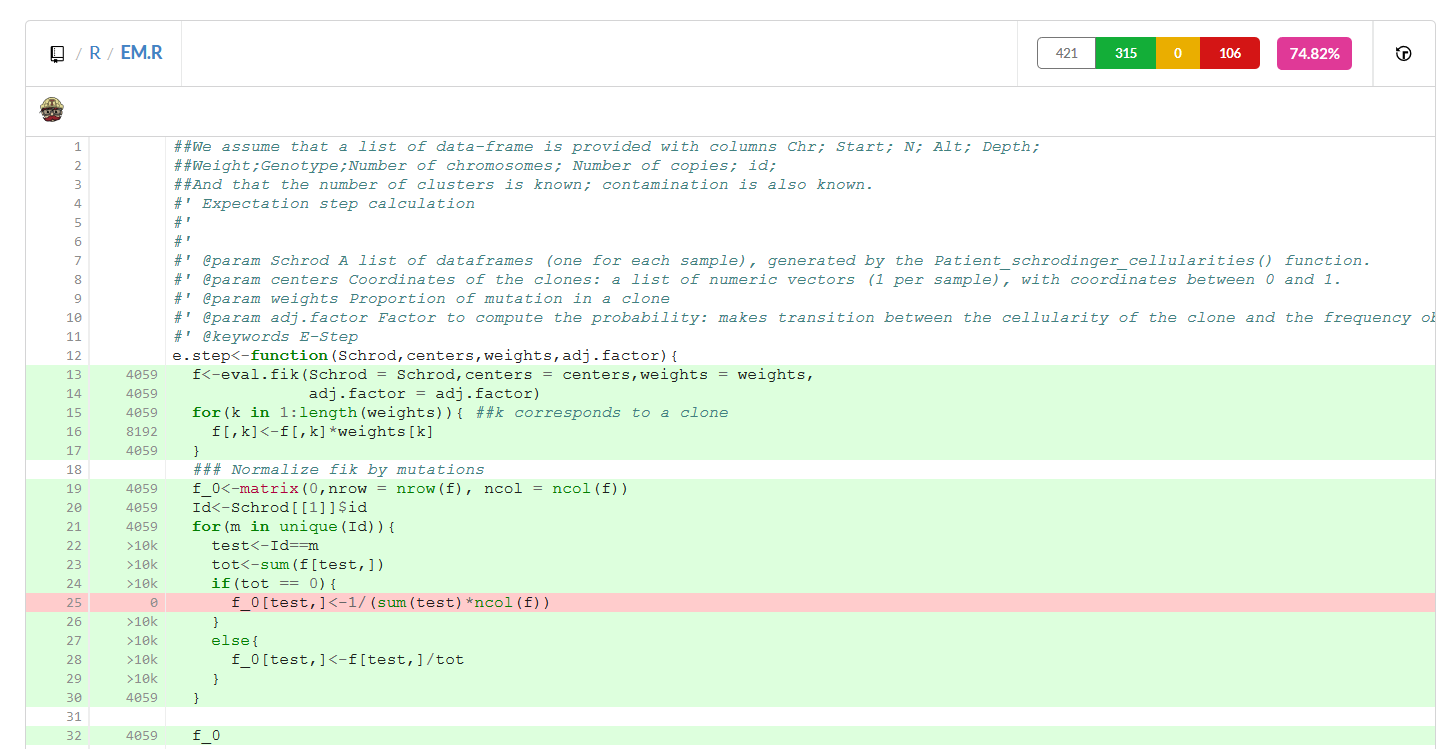
Lines in green are covered, white lines are comments or documentation and not taken into account, and red lines are not covered. We can see in the upper right part that in the EM.R file, 106 lines are not covered (or 74.82% are covered, if you are optimistic).
What’s a good test?
Tests can be errors you have found and corrected - remember this pesky bug you spent days correcting? You don’t want to have it again, do you? Or simply good examples you had: is your clustering correctly working on simple examples? Do you correctly throw an error for your regression if a single data point is given? It’s also a very good way to reflect on your package.
Additional bonus
If, like many people I know, you have a gigantic package with a lot of functions that you just use for your analyses, some of it may become outdated. With unit testing you can see what part of your code is used by the tests and what is not, so you can clean a posteriori.
Conclusion
- You can test for cases where you know there was an issue, and make sure it never appears again. This is good for pipelines that have known false positives or negatives that you know you can avoid;
- People can have a look at the code, see that it’s robustly tested and will want to use it;
- You gain a lot of time when you have to edit your code, and you’re much more confident in what you just posted!
BONUS
Here is my full codecov.yml:
comment: false